Research
Broad Motivation
The recent success of deep learning has had a massive impact on our lives. The release of AlexNet, the winner of the Large Scale Visual Recognition Challenge in 2012, revitalized deep learning research. As a result, deep neural networks have achieved state-of-the-art results in various fields, often surpassing human level accuracy and even beating world champions at their own strategy games. Today, most of the 'intelligence’ achieved by deep nets is deployed on the cloud, where compute resources are abundant. However, there is an ever growing interest in bringing this intelligence to the resource-constrained Edge, a requirement for many applications such as autonomous driving for instance. Deploying deep nets at the Edge imposes strict limitations on their complexity, which translates to sub-par performance. Furthermore, it has been observed that deep nets are inherently vulnerable to adversarial perturbations. Well-crafted imperceptible perturbations can fool undefended networks with deterministic success. These two challenges have been addressed mostly in isolation, with very few works proposing techniques for efficient and robust deep nets. My research aims at bridging the gap between accuracy, robustness and complexity, via a cross-layered approach utilizing circuit, architectural, and algorithmic level techniques.
Adversarial Vulnerability of Randomized Ensembles - ICML 2022
This work was accepted for publication in International Conference on Machine Learning (ICML) in 2022. You can find the paper here, as well as our code, slides, and poster.
Abstract
Despite the tremendous success of deep neural networks across various tasks, their vulnerability to imperceptible adversarial perturbations has hindered their deployment in the real world. Recently, works on randomized ensembles have empirically demonstrated significant improvements in adversarial robustness over standard adversarially trained (AT) models with minimal computational overhead, making them a promising solution for safety-critical resource-constrained applications. However, this impressive performance raises the question: Are these robustness gains provided by randomized ensembles real? In this work we address this question both theoretically and empirically. We first establish theoretically that commonly employed robustness evaluation methods such as adaptive PGD provide a false sense of security in this setting. Subsequently, we propose a theoretically-sound and efficient adversarial attack algorithm (ARC) capable of compromising random ensembles even in cases where adaptive PGD fails to do so. We conduct comprehensive experiments across a variety of network architectures, training schemes, datasets, and norms to support our claims, and empirically establish that randomized ensembles are in fact more vulnerable to lp-bounded adversarial perturbations than even standard AT models.
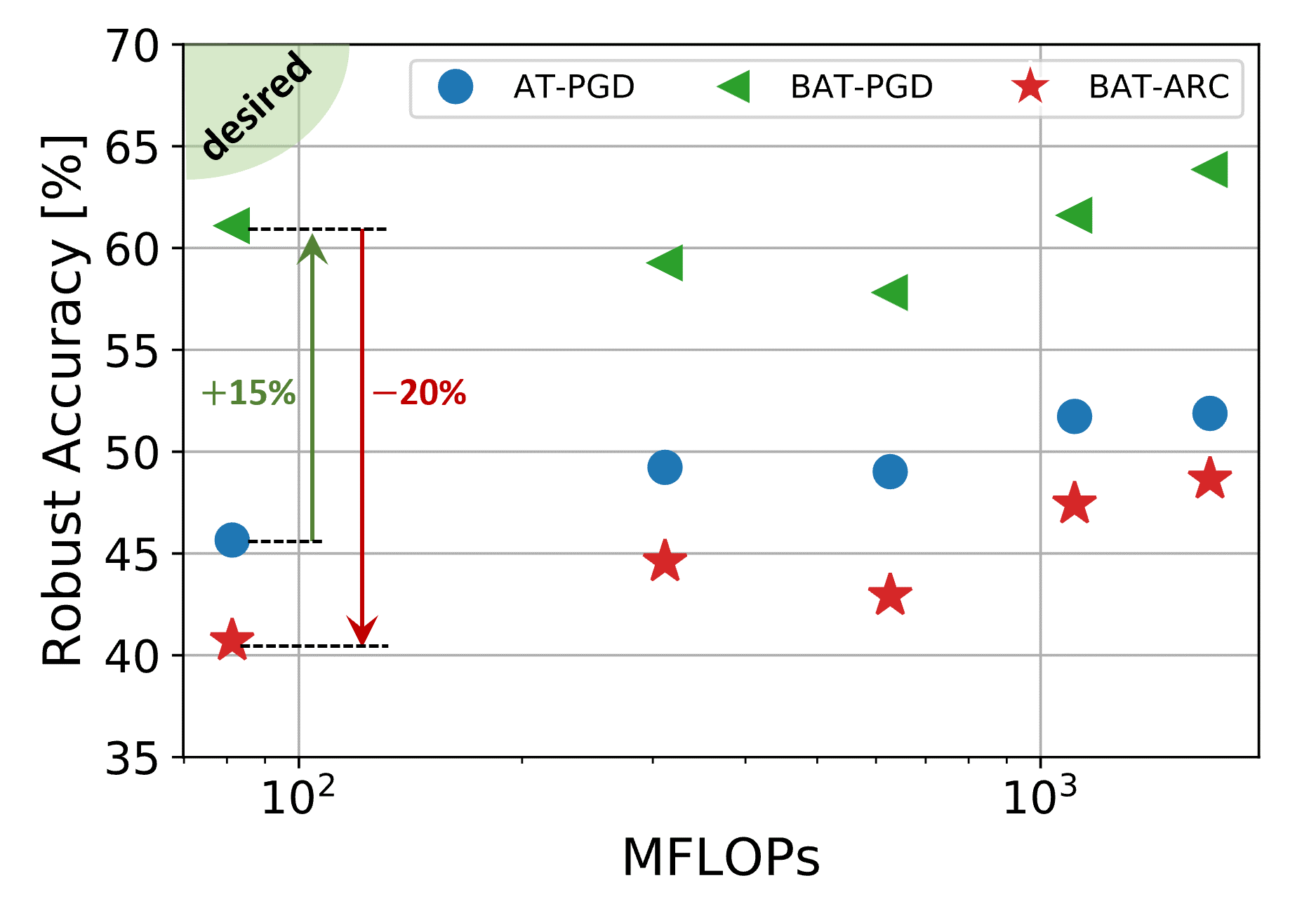 |
Generalized Depthwise-Separable Convolutions for Efficient and Robust Neural Networks - NeurIPS 2021 (Spotlight)
This work was accepted for publication as a Spotlight paper in Advances in Neural Information Processing Systems (NeurIPS) in 2021. You can find the paper here, as well as our code, slides, and poster.
Abstract
Despite their tremendous successes, convolutional neural networks (CNNs) incur high computational/storage costs and are vulnerable to adversarial perturbations. Recent works on robust model compression address these challenges by combining model compression techniques with adversarial training. But these methods are unable to improve throughput (frames-per-second) on real-life hardware while simultaneously preserving robustness to adversarial perturbations. To overcome this problem, we propose the method of Generalized Depthwise-Separable (GDWS) convolution – an efficient, universal, post-training approximation of a standard 2D convolution. GDWS dramatically improves the throughput of a standard pre-trained network on real-life hardware while preserving its robustness. Lastly, GDWS is scalable to large problem sizes since it operates on pre-trained models and doesn't require any additional training. We establish the optimality of GDWS as a 2D convolution approximator and present exact algorithms for constructing optimal GDWS convolutions under complexity and error constraints. We demonstrate the effectiveness of GDWS via extensive experiments on CIFAR-10, SVHN, and ImageNet datasets.
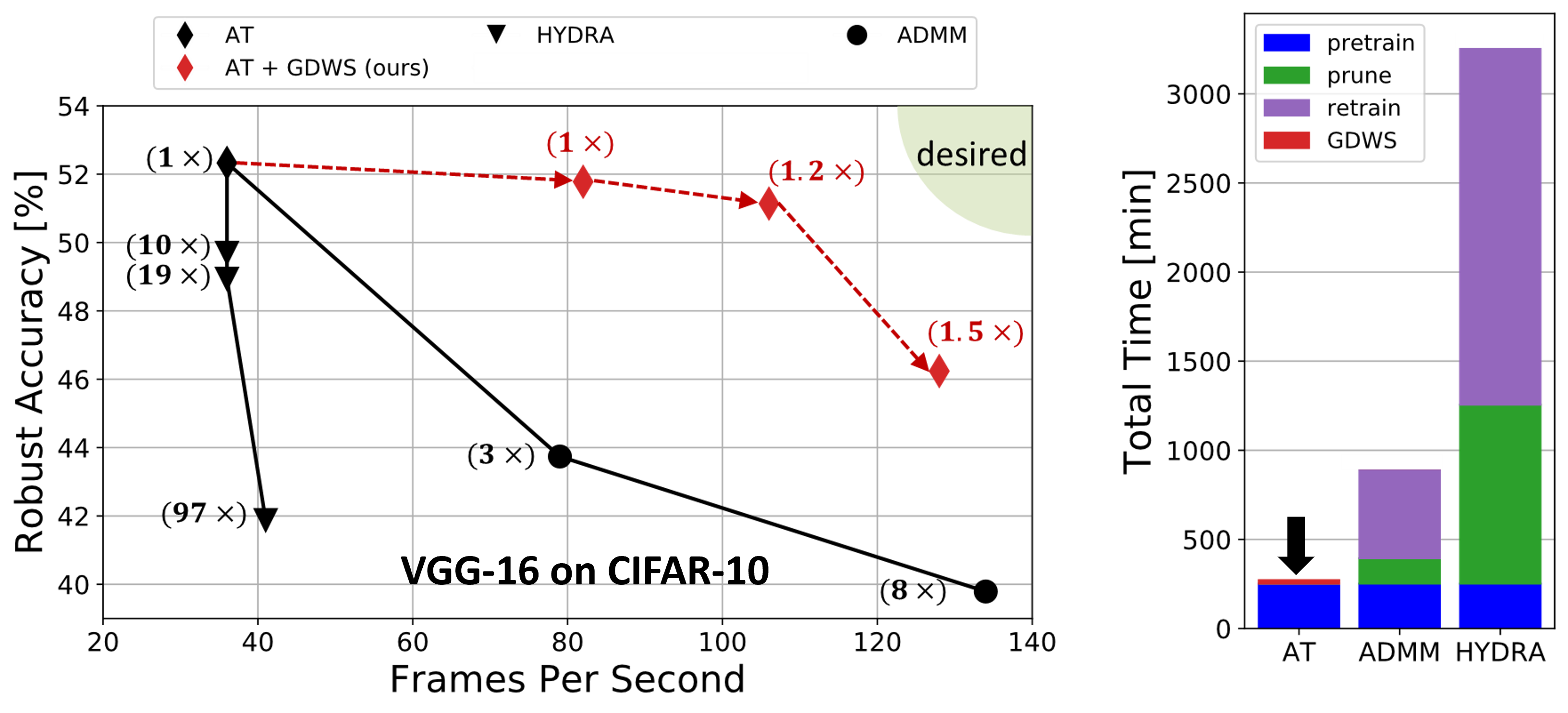 |
A Differentiable Branch Quantizer for Lightweight Deep Neural Networks - ECCV 2020
This work was done in collaboration with Mahesh Mehendale's team at Kilby Labs, Texas Instruments, while I was interning there in the summer of 2019. This work was published as a conference paper at the European Conference on Computer Vision (ECCV) in 2020. You can find an arxiv preprint here, as well as our slides.
Abstract
Deep neural networks have achieved state-of-the art performance on various computer vision tasks. However, their deployment on resource-constrained devices has been hindered due to their high computational and storage complexity. While various complexity reduction techniques, such as lightweight network architecture design and parameter quantization, have been successful in reducing the cost of implementing these networks, these methods have often been considered orthogonal. In reality, existing quantization techniques fail to replicate their success on lightweight architectures such as MobileNet. To this end, we present a novel fully differentiable non-uniform quantizer that can be seamlessly mapped onto efficient ternary-based dot product engines. We conduct comprehensive experiments on CIFAR-10, ImageNet, and Visual Wake Words datasets. The proposed quantizer (DBQ) successfully tackles the daunting task of aggressively quantizing lightweight networks such as MobileNetV1, MobileNetV2, and ShuffleNetV2. DBQ achieves state-of-the art results with minimal training overhead and provides the best (pareto-optimal) accuracy-complexity trade-off.
 |
A Recurrent Attention In-memory Processor for Keyword Spotting - CICC 2020 & JSSC 2021
This work was done in collaboration with my colleagues Dr. Sakr and Dr. Gonugondla. A conference version of this work was first presented at the Custom Integrated Circuits Conference (CICC) in 2020, with a follow-up journal publication in the Journal of Solid-State Circuits (JSSC) in 2021. You can find the CICC preprint here alongside the slides, as well as our JSSC preprint here.
Abstract
This work presents a deep learning-based classifier IC for keyword spotting (KWS) in 65nm CMOS designed using an algorithm-hardware co-design approach. First, a Recurrent Attention Model (RAM) algorithm for the KWS task (the KeyRAM algorithm) is proposed. The KeyRAM algorithm enables accuracy vs. energy scalability via a confidence-based computation (CC) scheme, leads to a 2.5× reduction in computational complexity compared to state-of-the-art (SOTA) neural networks, and is well-suited for in-memory computing (IMC) since the bulk 89% of its computations are 4b matrix-vector multiplies. The KeyRAM IC comprises a multi-bit multi-bank in-memory computing (IMC) architecture with a digital co-processor. A sparsity-aware summation scheme is proposed to alleviate the challenge faced by IMCs when summing sparse activations. The digital co-processor employs diagonal major weight storage to compute without any stalls. This combination of the IMC and digital processors enables a balanced trade-off between energy efficiency and high accuracy computation. The resultant KWS IC achieves SOTA decision latency of 39.9-μs with a decision energy <0.5 μJ/dec which translates to more than 24× savings in the energy-delay product (EDP) of decisions over existing KWS ICs.
 |